■2項分布のムラについて考える 
今回の目的を説明するために、少し準備を行う。
まず、2048個の[ランダムに0から256の値を持つもの]からなる1次元データを作成する。以下の左図がそのデータである。ここで、X軸がデータの順番であり、1から2048までを示し、Y軸がデータの値である。Y軸の数値ラベルは0から256の値である。折れ線グラフの方が1次元データとして実感できるのだが、そうすると真っ黒になってしまうので、点プロットグラフにしてある。
また、[0から256]のデータの出現頻度のグラフ(つまりヒストグラム)を右の図として示す。
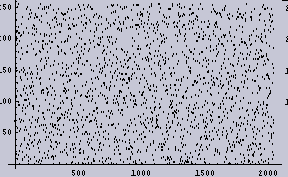 | 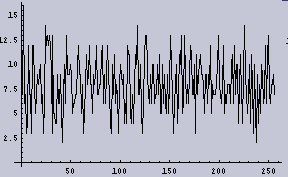 |
右のグラフを見ると、下は2回から上は15回位の間で出現頻度がばらついている。その頻度のムラは分散として計算することができる。今回の場合は2項分布である。
今回の目的は、そのムラを考えることである。広い範囲で見たときには、どの程度フラットだろうか。例えば、最初の100個のデータの平均と、次の100個のデータの平均というのはどの程度同じだろうか。それが1000個ならどうだろうか。1000個平均してみても場所によって、平均値はばらついているだろうか。もし、ばらついているとしたら、2項分布の確率過程を導入すると、広い範囲で見てみても認識できるくらいのばらつきを導入していることになる。その「ばらつき=ムラ」を人間が感じないためには、どの程度まで平均しなければならないのか。そういったことである。
ここで、先の2048個の1次元データは2048dpiの1次元画像データである、ということにしてみる。したがって、X軸の領域はトータル1inchを示すことになる。そして、以下の作業をする。
- 2048dpiの1次元画像データを2値化(128でしきい値とした)したものを8個に分断する。
- それぞれ、分断したデータ(256個)内で平均を取る。そなわち、8ppi(pixelper inch)の1次元データができる。
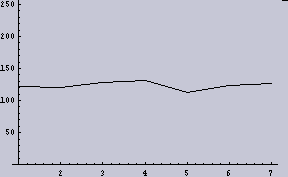 | 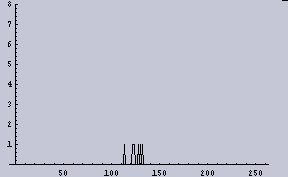 |
すると、2048dpiの(1/2の確率で2値化された)データというものは、今回の目的である「ムラを感じないための条件」を満たしていないということになる。ここでは画像に例えているが、別に画像だけの話ではない。
それでは、いくつか条件を振ってみたい。各々の条件下で示すグラフの領域は以下を示す。
| オリジナルの1次元データ | 左のヒストグラム。条件違いで軸が揃ってないのに注意。 |
| 8ppiに変換したもの Y軸はいずれも相対値であることに注意。Max=256と読み直す。 | 左のヒストグラム X軸はいずれも相対値であることに注意。Max=256と読み直す。 |
| オリジナルの1次元データ | 左のヒストグラム |
| 8ppiに変換したもの | 左のヒストグラム |
オリジナルの1次元データ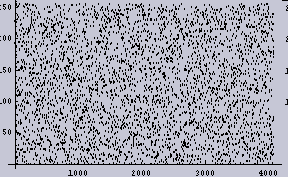 | 左のヒストグラム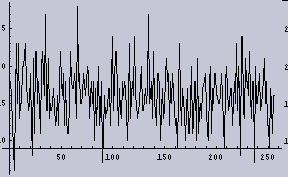 |
8ppiに変換したもの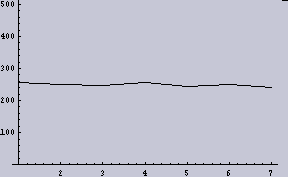 | 左のヒストグラム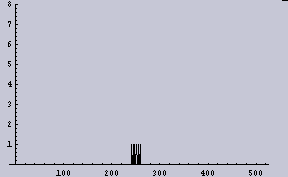 |
オリジナルの1次元データ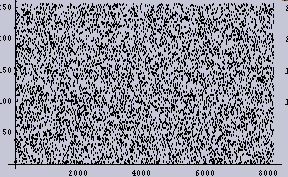 | 左のヒストグラム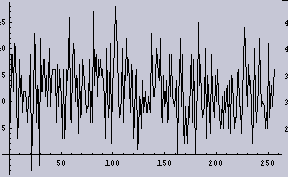 |
8ppiに変換したもの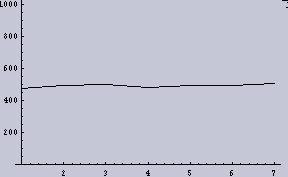 | 左のヒストグラム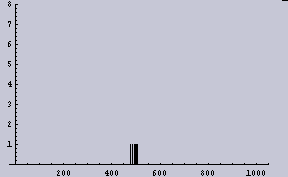 |
上の右下で出ているようなヒストグラムが2項分布であることは、サンプルを多く(しかし、試行回数を少なく)すればよくわかる。例えば、このようになる。
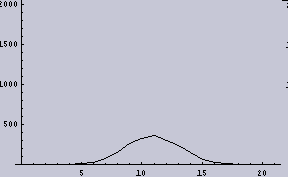

今回の話はあることの前準備なので、これだけでは話しが全く見えないかもしれない。というわけで、