1999-11-01[n年前へ]
■踊る人形 
郵便カスタマバーコードFontを作る
久しぶりの新宿の東急ハンズでこんなものを買った。
 |
紫外線を発光する蛍光灯である。ブラックライトという名称の方が通りが良いかもしれない。ブラックライトを車につけている人も多いらしい(私の趣味には実に合わないのだが)。スケルトンという所が今風である。
さて、このブラックライトを使って「何か手元にあるものでテストをしよう」というわけで、はがきを照らしてみた。すると、「踊る人形」のような模様が浮かび上がる。
 | 自宅に届いたはがきをブラックライトで照らしてみる。 |
 照らす前 |  照らしているところ バーコードが見える |
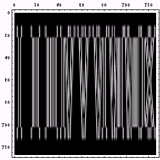
もちろん、これはバーコードである。これは、郵便局の新型区分機により印刷される不可視の「局内バーコード」と「IDバーコード」だ。真っ直ぐな線が続いているのが、「局内バーコード」で、「踊る人形」みたいのが「IDバーコード」である。
一番、目に触れているであろう「カスタマバーコード」(料金割引を受けようとする際に、差出者が郵便物に印字するバーコード)の写真を出したかったが、手元にないのだ。私の自宅にバーコード付きで手紙を出してくる人なんかいないのである。じゃぁ、勤務先はどうかというと、こちらは実に田舎で「字(あざ)」まであるのだ。困ったものだ。というわけで、こちらにも「カスタマバーコード」を印字したものは届いていない。
最初は、「局内バーコード」と「IDバーコード」を解読しようかと思ったのだが、探してみると詳細な情報がすでにある。
- 郵便バーコード (http://www2.biglobe.ne.jp/~t-iwata/barcode/bar_code.htm )
当初は、「局内バーコード」と「IDバーコード」のフォントを作成するつもりだった。不可視のフォントという所にロマンが感じられる。しかも、普通の人は使わなく、作っても無駄なところが本WEBにぴったりである。しかし、あまりに用途が限られてしまうので、まずは「カスタマバーコード」のフォントを作成することにした。もちろん、「局内バーコード」と「IDバーコード」も近いうちに作成する予定である。
それでは、まずは
- TTEditの紹介( http://www.interq.or.jp/www1/anzawa/ttedit.htm )
そして、作成したのフォントが以下である。「バーコード」のような、文字数が少ないものは作成するのは簡単である。 フォントの対応を下に示す。
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 0 | - | CC1 | CC2 | CC3 | CC4 | CC5 | CC6 | CC7 | CC8 | Start | Stop |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 0 | - | : | ; | < | = | > | ? | @ | A | B | C |
ところで、カスタマバーコードの規格は結構厳しいらしい。このフォントが規格をみたしているかどうかは、怪しいものだ。自分で言うのもなんだが、テストすらしていない。テストするのは「またいつかの回」ということにしておこう。あるいは、動作確認、不動作確認などして下さった方がいらっしゃれば、ご一報頂けると幸いである。
2000-01-21[n年前へ]
■数字文字の画像学
縦書きと横書きのバーコード
始まりはまたしても「物理の散歩道」である。
- 「新物理の散歩道」 第一集 ロゲルギスト 中央公論社
さて、その中の-横組・縦組と二つの目-という一節中の外山滋比古氏の発言が実に面白い。
「日本の漢字は横の線が発達してますから、横から読みますと目に抵抗が少なくて読みにくいですね。ヨーロッパの文字は縦の線が非常に発達していて、横に読むと非常に能率がいいわけです。数字でも縦の棒を引いて、Ⅰ、Ⅱ、Ⅲ、Ⅳ....としますが、和数字は横に線を引いて一、二、三...となります。...」という発言である。
- 文字は読む方向に対して垂直な線が多い
- また、読む方向に対して水平な線は少ない
- いずれも目のスキャン方向に対して垂直な線が多い
そこで、今回その確認と考察を行ってみることにした。サンプルとしては、外山滋比古氏の発言の通り、ローマ数字と漢字数字を用いることにする。
まずは、本来の書き方の方向に数字を並べた画像である。画像サイズは128x128である。後の処理のために、縦横比を同じにした。すなわち、本来の画像のアスペクト比とは異なる。
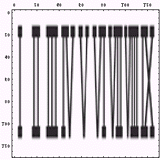 |  |
この二つの画像を読む方向に目を走らせると、まるでバーコードのようである。以前、
の時に作った郵便カスタマバーコードを参考に示してみる。考えてみると、バーコードは検出手段をバーコードの進行方向に走らせて、情報を読み取るわけである。人間が数字の羅列を読み取るのも、数字文字列上に目を走らせるのであるからまったくもって同じである。
一次元バーコードを考えた時、バーコードのバーは進行方向に対して垂直なものがほとんどである(若干のアジマス角を持つものもあるが)。バーコードを読み取る方向に対してのみ情報が書き込まれているのだから、それ以外の方向には等方的であるのが当然である。もし、そうでなかったらスキャン位置がちょっとずれただけでデータの読み取りができなくなってしまう。
そう考えると、先の数字文字に関する
- 読む方向に対して垂直な線が多い
- 読む方向に対して水平な線は少ない
また、本来の数字文字を並べる方向が読み書きの方向と異なる場合を以下に示す。
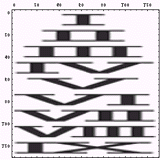 |  |
さて、画像を並べるだけではつまらないので、
- 本来の書き(並べ)方
- 本来の書き方と異なる書き(並べ)方
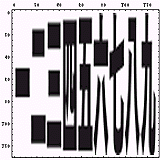
人間の目が数字文字列上をスキャンしていくときに、選られる情報量を考えるために、読む方向に対して画像を微分したものを示す。もう少し正確に言えば、微分値の絶対値を画像にしたものである。
まずは、本来の書き(並べ)方のものを示す。
 818892 | 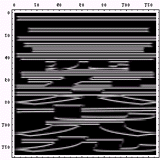 923836 |
微分画像の下に示した数字は微分(して絶対値)画像のピクセルの値の総和である。これをスキャン方向に対して選られる情報量の指標として扱うことにする。「スキャン方向に対して変化量が大きいということは、情報量が多い」ということだからである。
次に、本来の書き方と異なる書き方の場合を示す。
 536383 | 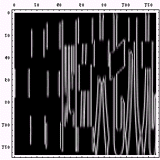 632338 |
それでは、「微分(して絶対値)画像のピクセルの値の総和」を比較してみることにしよう。
| 本来の書き方の場合 | 818892 | 923836 |
| 本来の書き方と異なる場合 | 536383 | 632338 |
ローマ数字、漢字数字の両方で、本来の書き方の方が(読む方向に対する)画像の変化量が大きいことがわかる。すなわち、「目のスキャン方向に対して選られる情報量」が多く、そうでない方向には冗長なのである。エラー発生率が小さくなるのである。本当にバーコードそのものである。文字はバーコードの祖先だったのである。
さて、「文字の画像学」も色々と面白そうなので、これからちょこちょこ遊んでいこうと思う。
2000-01-27[n年前へ]
■「富士の樹海」を目指せ
磁界を可視化しよう
以前から探していた「面白いもの」を入手した。この写真がその「面白いもの」なのであるが、何だかわかるだろうか? ちなみに、大きさは「1cm×5cm」位のシートである。
 |
これは「マグネビュアー」というものである。磁界を可視化してくれるシートだ。マイラーフィルムの間に磁性体を混入させたマイクロカプセルを入れることで、磁界に対する配向性を持たせたものだ。と、言葉でいってもなかなかわかりにくいので、磁界を可視化した写真を示してみる。何しろ、百聞は一見に如かずである。
次の写真は某ピザ店のマグネットシート(よく冷蔵庫の扉に張り付ける奴)の上に「マグネビュアー」をのせたところである。ピザ屋は私の食生活を支えていると言っても良い。私が生きているのはピザ屋のおかげである。
 |
私の「命の恩人」でもある某ピザ店のマグネットシートがつくる磁界が見て取れるだろう。磁界が可視化されているのである。
本WEBではこれまで様々な「可視化」で遊んできた。例えば、
- 感温液晶でNotePCの発熱分布を可視化する
- ハードディスクのエントロピーは増大するか?- デフラグと突然変異の共通点 - (1999.03.28)
- 夏目漱石は温泉がお好き? -文章構造を可視化するソフトをつくる - (1999.07.14)
- 恋の力学 -恋の無限摂動 - (1999.12.21)
- WEBサイトの絆 - WEBの世界を可視化しよう- (2000.01.13)
- 夜のバットマン - 超音波を可視化しよう- (2000.01.17)
上に示した「某ピザ店のマグネットシートの表面」の磁界の様子も面白いが、もっと面白いのは「某ピザ店のマグネットシートの境界」の磁界を可視化したものである。
それが下の写真である。磁界の様子が実感できるのではないだろうか?
 |
下に示す図はドーナツ型の磁石の周りの磁界をCUPSを用いてシミュレーション計算した結果である。この計算結果と同じようなものが「マグネビュアー」を使うと簡単に可視化できる。
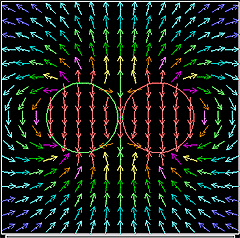 |
普通、こういった磁界の可視化は磁気造影剤や砂鉄みたいな磁性体粒子を用いるのであるが、そういったものはどうにもハンドリング性にかける。液体や粉体などを家の中で実験に使うのはイヤである。いや、もちろん仕事で使うのもイヤであるが... そこで、この「マグネビュアー」が登場するわけだ。
それでは、その他の面白そうな磁界を可視化してみたい。磁界と言えば、やはりアレの登場だろう。もちろん、アレと言えば磁気カードである。クレジットカードや銀行のキャッシュカードといった磁気カードだ。一例を次に示してみる。こんなヤツだ。
 |
カードの下に黒い磁気データ記録部があるのがわかるだろう。
それでは、その「磁気データ記録部」に「マグネビュアー」をのせてみよう。はたして、磁気データは可視化されるだろうか?
 |
といっても、この写真ではわかりにくいので、「マグネビュアー」を拡大してみよう。すると、バーコードのような模様が見えるのがわかると思う。「磁気データ」が簡単に可視化されているわけである。この「マグネビュアー」と普通のスキャナーがあれば磁気データ読み取り機がなくても磁気データが読みとれるのである。
 |
しかし、このカードに関しては内容を解析するとマズイ事情があるので、次回に「ソフマップ」のカードを題材にして磁気カードの内容を可視化してみるつもりだ。題して、
- ソフマップでお買い物 - 磁界の可視化とバーコード - (仮称)
さて、話は変わるが、私はこの「マグネビュアー」を手に「富士の樹海」を目指すつもりだ。「富士の樹海」では」方位磁針が変な方向を示すと伝えられている。そしてまた「富士の麓」ではとかく人は判断を誤りやすいとも聞く。船頭多くして船山に登ると言うが、「富士の樹海」には判断を誤った船が沈没しまくりである。
私は「富士の樹海」の真実をこの「マグネビュアー」で明らかにするつもりだ。「富士の樹海」の謎を明らかにするのである。何故、方位がそして人が判断を誤るのか、その謎を明らかにするのだ。
しかし、もしも、もしも、の話であるが、本WEBの更新が止まった際には、「富士の樹海」で私が眠っていると思って欲しい。「マグネビュアー」が役に立たないはずがないのだが、きっと何か判断を間違えたのであろう。そうそう、あくまで「富士の樹海」である。「富士の裾野」ではないので念のため...
2000-01-30[n年前へ]
■ソフマップでお買い物
磁界の可視化とバーコード
前回、
で「マグネビュアー」を使って磁界の可視化をして遊んでみた。今回はその続きである。ソフマップの磁気カードの中に書き込まれている磁気データを可視化して調べてみるのである。磁気カードには、
- 銀行のキャッシュカード
- クレジットカード
- テレホンカード
- オレンジカード
まずは、ソフマップカードの写真を示してみよう。これがソフマップで買い物をするたびにお世話になるソフマップカードである。
 |
この写真からではどこにデータが書き込まれているのかわからない。そこで、「マグネビュアー」の登場と言いたいところであるが、残念ながら今回は「マグネビュアー」は登場しないのである。「マグネビュアー」はとても便利なのであるが、さすがに磁気カードの磁気データを読もうとすると分解能が不足する恐れがある。
そこで、代打選手に登場願うことにした。代打選手はキヤノン製のLBPのトナーである。以前、
の時に「トナーはクーロン力で制御されて画像を作るのだ」という話があった。キヤノン製の白黒のLBPではクーロン力に加えて磁気力を使ってトナーを制御している。なので、キヤノン製の白黒トナーは磁性体粉末ということになる。テレホンカードが出た頃はキヤノン製のトナーを使ってデータを読み出していた人も多いはずである。みな、テレホンカードの表面を削りトナーを振り掛けていたのである。というのは、聞いた話であり、実体験に基づくものでは絶対にない。神に誓っても良い。その頃にキヤノン製のトナーを使い倒していたということは絶対にないのである。しかも、その数年後に(以下略)。
それでは、磁性体の微少粉末であるトナーをソフマップカードに振り掛けてみよう。
 |
ソフマップカードの磁気データが可視化されたのがわかると思う。磁気によるバーコードが見えるだろう。これがソフマップカードに書き込まれている磁気データである。
とはいえ、トナーの付着具合にムラがある。それは私が雑に実験を行ったからである。こんなにムラがあっても磁気コードが判別できるかどうか疑問を持たれる方も多いと思う。しかし、
- 読む方向に対して垂直な線が多い
- 読む方向に対して水平な線は少ない
そのようにして、ノイズを減らし、S/N比を上げた画像を示してみる。
どうだろうか、驚くほど綺麗になっているのがわかると思う。まさか、と思われるかもしれないが本当である。
さて、これはソフマップカードの磁気データの全体像であるが、もう少し拡大したものを以下に示す。
 |
極めて明瞭に磁気データが可視化されているのがわかると思う。これはトナーを振りかけて、1万円ちょっとのスキャナ(CanonのUSB接続の安物スキャナ)で読み込んだものに対して先の処理をしただけである。これほど明瞭になるのも、全て1次元バーコードの特徴のおかげである。磁気ヘッドの制作などをしなくても良いのである。
磁気カードの記録密度は銀行統一仕様(NTT)でもISO3554でも8.3bit/mm=211bit/inchであるから、最近の600dpi(dot/inch)程度のスキャナーであれば十分磁気データの画像読みとりが可能である。
それでは、もっと拡大してみる。拡大する部分は上の画像の右の辺りである。すると、このようになる。
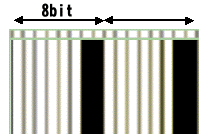 |
データ間隔がわかりやすいように、ここでは矢印や文字を書き入れている。この画像を見ると、磁気データは規則的な細かい周期性を持ち、その周期でいうと8つ単位でさらなる周期性があるように思われる。つまり、8bitをひとまとまりとしたデータが書き込まれているように見える。例えば、上の画像では
- ( 白、白、白、白、白、白、黒、黒 ) x 2
- ( 00000011 ) x 2
- ( ああああああたた ) x 2
複数枚のカードのこの部分を比較してみれば、比較的容易にデータ構造は解析することができるだろう。また、一枚のカードからでもカード番号などの数字と磁気データを比較することにより、解析することはやはり困難無しに解析できると思うのである。と、思うわけではあるが、あまりやりすぎるのはマズイと思われるので、今回はこれまでにしておく。
2001-04-29[n年前へ]
■ファイト!縦文字文化
縦と横の解像度を考えよう
今年も去年に引き続き英語研修を受けている。といっても、去年は毎日十五分の英語研修だったが、今年は週二日のものを二種類受けている。何事も、「一番弱いところを強くするのが一番」というわけで、それが私の場合は英語であるわけだ。いや、もちろん弱いところは数え切れないほどあるのだが、英語はもうどうしようもないくらいダメなのである。
その英語研修を受ける中で、本当に実感するのが「頭の中でも英語で考えないとキツイ」ということである。頭の中で日本語で考えてから英語で喋ろうとすると、その「日本語→英語変換」のオーバーヘッドはすさまじくて、とても会話にならないのである。もちろん、当然その逆もしかりで「英語→日本語変換」なんかもやっていたら、あっというまに相手の喋るスピードについていけず、「ここはどこ?私はだれ?」状態になってしまう。
もちろん、「頭の中で英語で考えられる位なら、そもそも苦労はせんのじゃぁ!」と叫びたくなることもしばしばあるわけで、実際のところ私にはどうしたら良いのか全然わからないのである。「頭の中に言いたいことは沢山あるけど、それを伝えられない状態」と「頭の中でたいしてものを考えることができない、それを伝えられる状態」とどっちかを選べと言われても困ってしまう。残念ながら、「英語で頭の中でビュンビュンと考えて、それが口からペラペラとでてくる」状態は私には遠い夢物語のようなのである。
こんな苦労は、日本語人生一本やりだった私が英語を使う場合にはどうしても避けられない話なのであるが、そんな「私の苦労」と似たような話はコンピュータの世界にも実はある。例えば、「今日の必ずトクする一言」でもよく登場する「Windowsの日本語化のオーバーヘッドに関する一連の話」などがそうである。超漢字あたりであれば話は別なのかもしれないが、Windowsに限らずどんなOSであっても英語だけを使うときと、日本語のような言語を使うときではスピードが全くと言って良いほど違ってしまう。
例えば、英語版のWindowsであれば最新型のPCでなくてもサクサク動くのであるが、これが日本語版のWindowsともなると、最新型のPCでなければカタツムリのようなスピードに変わってしまうのである。最新型のWindowsやMacOS***の推奨マシンスペックは○×○×です、とOSメーカーが言ったところで、それは英語圏での話で日本語人生の私のようなものにはそれは当てはまらないのだ。わずか100文字ほどのアルファベットですむ英語の場合と、約七千字ほどもある日本語を使う場合とでは文字・フォント処理のスピードが違ってしまうのは当たり前の話である。
ところで、英語と日本語をコンピューターなどで扱う時の大変さというものは文字数だけの話なのだろうか?数が多いから大変なのは当たり前なのだが、それだけではないのではないだろうか。単に文字数が多いというだけではなくて、一つの文字当たりの情報量も日本語の方が遙かに多いと思うのである。例えば、アルファベットの中でも複雑な形をしている"M"と、日本語というか漢字の中でも結構複雑な形をしている「廳」を比べてみれば一目瞭然だろう。"M"よりも、「廳」の方がずっと複雑な形状をしている。
漢字の文字数が多いということは、そのたくさんある文字を区別するためにも漢字という文字の形状自体が複雑にならざるをえないわけで、それはすなわち漢字一文字の情報量はアルファベット一文字の情報量よりも遥かに多いということだ。ということは、
- 一文字辺りの情報量が多くて
- しかも文字数が多い
しかし、「PC内部での処理も大変ではあるが、それを外部に出すときも大変だろう」というのが今回の話のテーマである。モニタやプリンタに出力する時の大変さも英語と日本語では大違いで、しかも英語文化で考えると見えない落とし穴があるのではないだろうか、という話である。
まず、文字を表示するスペースというのは大体決まっている。そんな限られた同じスペースの中に、一文字辺りの情報量が少ないアルファベットと多い漢字を同じように詰め込めるだろうか?先ほどの"M"と「廳」を縮小して10pt程度にしてみると、その答えはすぐにわかる。アルファベットの"M"の方はちゃんと読めるとは思うが、漢字の「廳」の方がちゃんと識別できる環境の人がいるだろうか?PCの画面に表示されている「廳」はずいぶんと省略されたてしまっていたり、あるいは潰れてしまっていたりするはずである。
つまりは、PCの内部でも漢字のような文字を扱うのは大変であるが、それを外部へ表示したりするのも実際問題大変なのである。英語圏のアルファベット文化から考えれば、10ptなんて大きくて読みやすいと思うのかもしれないが、漢字などを考えると今のモニタの解像度では10ptでも小さすぎるのである。逆にいえば、アルファベットなどを表示する時に比べて漢字などの文字を表示する時には、遥かに高い解像度のモニタが必要とされるのである。PC自体の能力だけではなくて、モニタなどの出力機器も遥かに高い能力が必要とされるわけだ。
もちろん、それは漢字だけの話ではない。世界中の文字で当てはまるハズの話である。試しに、
- 世界の文字 (http://www.nacos.com/moji/)
 | 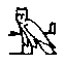 |  |
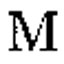 |  | 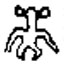 |
アラビア文字あたりはラテン文字であるアルファベットと同じ程度の複雑さであるが、その他の文字はやはり遥かにアルファベットよりも複雑な形状をしている。「この中の半分くらいは使われていない文字じゃねぇーか!」という声も聞こえてきそうな気もするが、そんな小さいことを気にしてはいけない、とにかくアルファベットは色々ある文字の中でも単純な形状をしていて、漢字は複雑な形状をしているのである。
次に、それぞれの文字画像の複雑さの特徴を眺めるために、それぞれ二次元フーリエ変換をかけて、周波数空間に変換してみたものを示してみることにしよう。まずは、漢字の例を示して図の見方を説明してみたい。
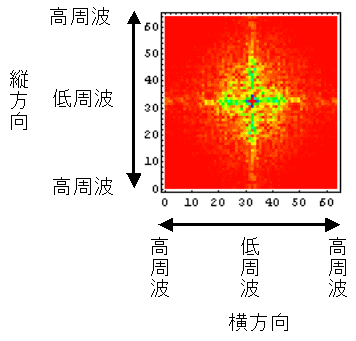 | 図の横・縦方向が実際の文字の横・縦方向に対応し、図の中で中央から外周方向に向かって低周波から高周波の成分の量を示している。強さは 小 ← 赤 黄 黄緑 青 紫 → 大の順番になっている。 たとえば、この漢字の例だと |
上の説明に書いたように、こんな風に文字画像を周波数空間に変換すると、「漢字は縦と横の線が多い」ということがよくわかる。しかも、
の時に調べたように、漢字は「縦方向に周波数成分が多い」、すなわち言い換えれば「横方向の線が多い」こともわかるのである。 さて、世界の文字六種に戻って、それぞれを周波数空間に変換して並べてみると、こんな感じになる。
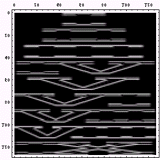
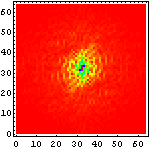 | 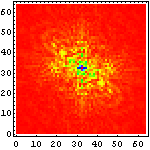 | 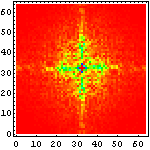 |
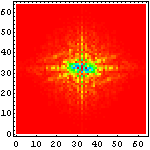 | 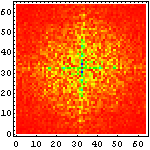 | 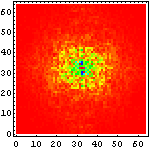 |
こうして六種の文字種を周波数空間に変換して眺めてみると、色々なことが判る。例えば、
- アラビア文字はほとんど高周波を含まない
- ヒエログラフは比較的高周波が少なく、方向性も持たない
- 漢字に含まれる高周波成分はほとんどが縦・横方向のみであり、その中でも「縦方向に周波数成分が多い」、すなわち言い換えれば「横方向の線が多い」
- アルファベットは低周波がメインであり、縦横では横方向の方が高周波を含んでいる、すなわち縦の線が多い
- マヤ文字は一番高周波まで含んでおり、比較的方向性も少ない
- ロンゴロンゴ文字はアラビア文字よりも高周波が多いが、それでも比較的低周波メインであり、方向性もない
もちろん、ラテン文字が比較的高周波が少ないからといって今の表示装置で十分だというわけではなくて、ラテン文字でもより高解像度のディスプレイが必要とされている。例えば、液晶画面などで文字を多量に読むことを想定している電子ブックなどの用途のためには、
で調べたMicrosoftの「ClearType」などの技術がある。これは液晶のRGBの画素の配列が横方向に並んでいることを利用して、横方向の解像度を高める技術である。ということは、こういう技術は横方向の高周波成分が多いラテン文字などでは効果が大きく、またラテン文字自体が比較的高周波成分が少ないために、こういう技術を使えば必要十分ということになるのかもしれない。しかし、日本語(漢字)のようなもともと高周波成分が多くしかもそれが縦方向に多い、というようなものでは効果は比較的少ないことが考えられる。もちろん、それは液晶というデバイスの特徴によるもので仕方のない部分もあるのだが、もしかしたらもしかしたら日本語のような縦方向の高周波を再現しなければならない言語のことを意識していないせいかもしれない。
こんなことは液晶などのモニタだけではなくて、一般的なプリンタもそうだ。例えば、インクジェットプリンタではエプソンのPM-900Cの仕様などを眺めてみても、標準で720×720dpiで、高画質モードでは1440×720dpiとなっている。それはレーザービームプリンタなどでも同じで、リコーのプリンター大百科からウルトラスムージングテクノロジーを見てみても、やはり横方向の解像度のみを高めて2400dpi×600dpiとなっている。やはり、プリンタなどの印字装置でも横方向の解像度を高めようとはするが、縦方向の解像度は低いままにしているのである。もちろん、縦方向の解像度を高くすると印字速度が遅くなってしまうという、プリンタの特性があるにしても、やはり日本語を印字するためには不利な設定となっているのである。日本人としては、解像度表示は縦方向を重視するべきで、横方向の解像度表示にダマされるべきではないのである。高解像度2400dpiなんて言われても、「ヘヘン、オレは縦文字文化の日本人だから関係ないんだもんね」くらいは言って欲しいわけである。
実際のところ、せっかく日本語(漢字)を使うのだから、日本語の特性に応じたPCやモニタやプリンタがあっても良いのになぁ、と思う。いや、というより日本語の特性をもっと理解するところから始めなければならないのかもしれない。そうだ、私はまずは日本語の勉強から始めるべきなのだ。英語の勉強をしている場合ではないし、頭の中で英語で考えていたりすると、縦文字文化に合った発想ができなくなってしまうに違いないのである。って、英語学習から逃げてるだけだったりして…
あぁ、しまったぁ。今回はホントに真面目な話になってしまったぞ、と。しかも、まるで国粋主義者みたいだし。