■夏目漱石は温泉がお好き? 
文章構造を可視化するソフトをつくる
先週は新宿で開催されていた可視化情報シンポジウム'99を見ていた。参加者の世界が狭い(ジャンルが狭いという意味ではない)し、学生の発表が多すぎるように思ったが、少なくとも本WEBのようなサイトで遊ぶには面白い話もあった。というわけで、これから何回か「可視化情報シンポジウム'99」記念の話が続くかもしれない。とりあえず、今回は「小説構造を可視化しよう」という話だ。
まずは、「可視化情報シンポジウム'99」の発表の中から一番笑わせて(笑ったのはいい意味ですよ。決して皮肉ではないですよ。しつこいようですが、ホントホント。私のツボに見事にはまったのだからしょうがない。)もらった発表のタイトルはこれである。
文学作品における文体構造の可視化 - 宮沢賢治「銀河鉄道の夜」の解析-
白百合女子大学大学院の金田氏らによる発表だ。予稿集から、その面白さを抜き出してみよう。まずは過去の研究の紹介をしている部分だ。
作品(hirax注:夏目漱石の「虞美人草」と「草枕」)の始まりから終わりまでを時系列で捉えると(hirax注:話法に関する解析をすると)、二作品はともに円環構造、つまり螺旋構造を描きながら、物語が進行していくことが、四次元空間上に表現された。
中略
これは、作品の解析結果を可視化することで、夏目漱石の思考パターンと内面の揺れが明らかにされたことを意味する。
なんて、面白いんだ。この文章自体がファンタジーである。こういうネタでタノシメル人にワタシハナリタイ。おっと、つい宮沢賢治口調になってしまった。そして、今回の発表の内容自体は、宮沢賢治の「銀河鉄道の夜」の中に出てくる単語、「ジョバンニ・カンパネルラ・二」という三つの出現分布を調べて構成を可視化してみよう、そしてその文学的観点を探ろう、という内容だ。
本サイトは実践するのを基本としている。同じように遊んでみたい。まずは、そのためのプログラムを作りたい。名づけて"WordFreq"。文章中の単語の出現分布を解析し可視化するソフトウェアである。単語検索ルーチンにはbmonkey氏の正規表現を使った文字列探索/操作コンポーネント集ver0.16を使用している。
ダウンロードはこちらだ。もちろんフリーウェアだ。しかし、バグがまだある。例えば出現平均値の計算がおかしい。時間が出来次第直すつもりだ。平均睡眠時間5時間が一月続いた頭の中は、どうやらバグにとって居心地が良いようなのだ。
wordfreq.lzh 336kB バグ有り版
バグ取りをしたものは以下だ(1999.07.22)。とりあえず、まだ上のプログラムは削除しないでおく。
失楽園殺人事件の犯人を探せ - 文章構造可視化ソフトのバグを取れ - (1999.07.22)
動作画面はこんな感じだ。「ファイル読みこみ」ボタンでテキストファイルを読みこんで、検索単語を指定して、「解析」ボタンを押すだけだ。そうすれば、赤いマークでキーワードの出現個所が示される。左の縦軸は1行(改行まで)辺りの出現個数だ。そして、横軸は文章の行番号である。すなわち、左が文章の始めであり、右が文章の終わりだ。一文ではなく一行(しかもコンピュータ内部の物理的な)単位の解析であることに注意が必要だ。あくまで、改行までが一行である。表示としての一行を意味するものではない。なお、後述の木村功氏から、「それは国語的にいうとパラグラフ(段落)である。」という助言を頂いている。であるから、国語用の解析を行うときには「行」は「段落」と読み替えて欲しい。また、改行だけの個所には注意が必要だ。それも「一行」と解釈するからである。
 |
「スムージング解析」ボタンを押せば、その出現分布をスムージングした上で、1行辺りに「キーワード」がどの程度出現しているかを解析する。
そう、この文章は長い文章の中でどのように特定の単語が出現するか解析してくれるのである。
それでは、試しに使ってみよう。まずは、結構好きな夏目漱石の小説で試してみたい。
電脳居士@木村功のホームページ
から、「ホトトギス」版 「坊っちやん」のテキストを手に入れる。そして解析をしてみよう。まずは、この画面は夏目漱石の「坊っちやん」の中で「マドンナ」という単語がどのような出現分布であるかを解析したものである。
|
文章の中ほどで「マドンナ」は登場してくるが、それほど重要なキャラクターでないことがわかる(このソフトがそう言っているんで、私が言っているのではない。だから、文句メールは送らないで欲しい)。
それでは、「湯」というキーワードで解析してみよう。「坊っちやん」と言えば道後温泉であるからだ。
 |
おやおや、「マドンナ」よりもよっぽどコンスタント(安定して、という意味で)に「湯」という単語は出現するではないか。出現平均値は「マドンナ」の方が多いが、安定度では「湯」の方が上だ。夏目漱石は「マドンナ」よりも「湯」すなわち温泉によっぽど興味があるようだ。
主人公を育てた重要人物「清」を調べてみると、こんな感じだ。
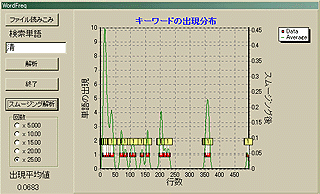 |
小説の初めなんか出ずっぱりである。あと小説のラストにも登場している。
どうだろうか。見事に小説の可視化に成功しているだろう。結構、この解析は面白い。すごく簡単なのである。
これから新聞、WEB、小説、ありとあらゆる文章を可視化し、構造解析していくつもりだ。みなさんも、このソフトを使って面白い解析をしてみるとよいのではないだろうか? とりあえず、高校(もしかしたら大学の教養)の文学のレポートくらいは簡単に書けそうである。もし、それで単位が取れたならば、メールの一本でも送って欲しい。
というわけで、今回はソフトの紹介入門編というわけで、この辺りで終わりにしたいと思う。