1999-01-08[n年前へ]
■2項分布のムラについて考える 
今回の目的を説明するために、少し準備を行う。
まず、2048個の[ランダムに0から256の値を持つもの]からなる1次元データを作成する。以下の左図がそのデータである。ここで、X軸がデータの順番であり、1から2048までを示し、Y軸がデータの値である。Y軸の数値ラベルは0から256の値である。折れ線グラフの方が1次元データとして実感できるのだが、そうすると真っ黒になってしまうので、点プロットグラフにしてある。
また、[0から256]のデータの出現頻度のグラフ(つまりヒストグラム)を右の図として示す。
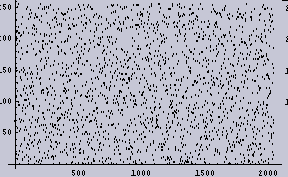 | 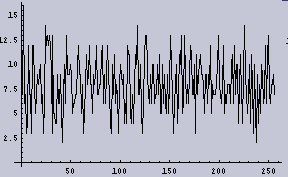 |
右のグラフを見ると、下は2回から上は15回位の間で出現頻度がばらついている。その頻度のムラは分散として計算することができる。今回の場合は2項分布である。
今回の目的は、そのムラを考えることである。広い範囲で見たときには、どの程度フラットだろうか。例えば、最初の100個のデータの平均と、次の100個のデータの平均というのはどの程度同じだろうか。それが1000個ならどうだろうか。1000個平均してみても場所によって、平均値はばらついているだろうか。もし、ばらついているとしたら、2項分布の確率過程を導入すると、広い範囲で見てみても認識できるくらいのばらつきを導入していることになる。その「ばらつき=ムラ」を人間が感じないためには、どの程度まで平均しなければならないのか。そういったことである。
ここで、先の2048個の1次元データは2048dpiの1次元画像データである、ということにしてみる。したがって、X軸の領域はトータル1inchを示すことになる。そして、以下の作業をする。
- 2048dpiの1次元画像データを2値化(128でしきい値とした)したものを8個に分断する。
- それぞれ、分断したデータ(256個)内で平均を取る。そなわち、8ppi(pixelper inch)の1次元データができる。
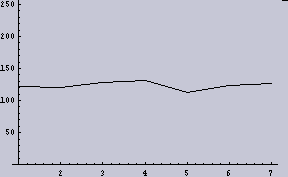 | 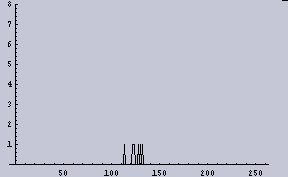 |
すると、2048dpiの(1/2の確率で2値化された)データというものは、今回の目的である「ムラを感じないための条件」を満たしていないということになる。ここでは画像に例えているが、別に画像だけの話ではない。
それでは、いくつか条件を振ってみたい。各々の条件下で示すグラフの領域は以下を示す。
| オリジナルの1次元データ | 左のヒストグラム。条件違いで軸が揃ってないのに注意。 |
| 8ppiに変換したもの Y軸はいずれも相対値であることに注意。Max=256と読み直す。 | 左のヒストグラム X軸はいずれも相対値であることに注意。Max=256と読み直す。 |
| オリジナルの1次元データ | 左のヒストグラム |
| 8ppiに変換したもの | 左のヒストグラム |
オリジナルの1次元データ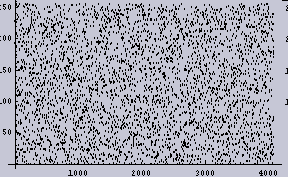 | 左のヒストグラム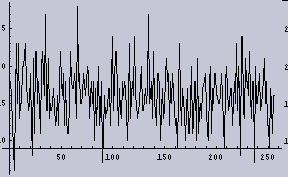 |
8ppiに変換したもの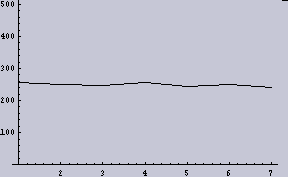 | 左のヒストグラム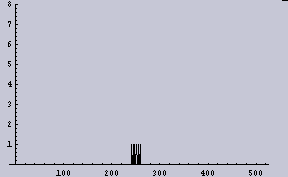 |
オリジナルの1次元データ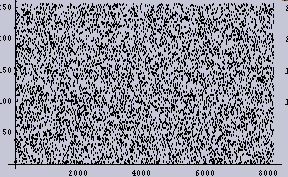 | 左のヒストグラム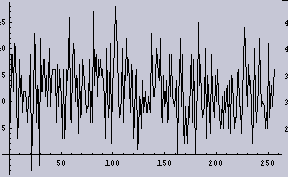 |
8ppiに変換したもの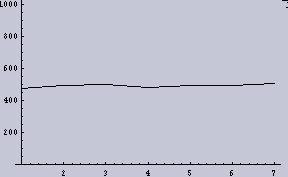 | 左のヒストグラム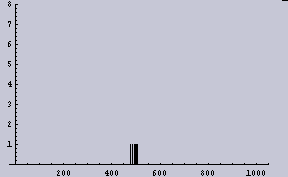 |
上の右下で出ているようなヒストグラムが2項分布であることは、サンプルを多く(しかし、試行回数を少なく)すればよくわかる。例えば、このようになる。
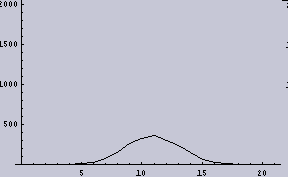

今回の話はあることの前準備なので、これだけでは話しが全く見えないかもしれない。というわけで、
1999-01-28[n年前へ]
■Photohoの落とし穴
ノイズフィルタに要注意
Phtoshopは大変巨大なソフトである。巨大すぎてよくわからないところも多い。巨大な割にはマニュアルは薄い。性能の割には安いと思うのだが、もう少し詳しいマニュアルも作って欲しい。Adobe(アドビでなくて)からなら入手できるのだろうが。
今回はPhotoshopの「ノイズフィルタ」について考えてみたい。 ノスタルジックにしたい時など重宝するフィルタである。
 |
 |
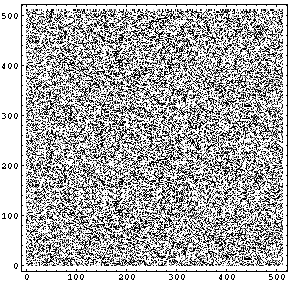
まず、「均等に分布」のノイズを見てみる。
 |
 |
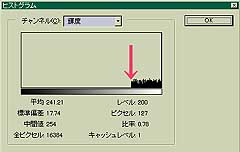 | 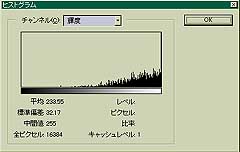 |
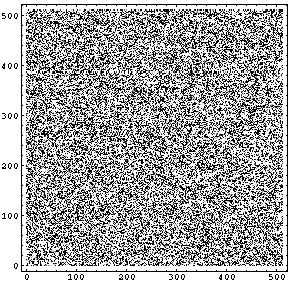
両方とも、「ノイズの量」を55にしてある。左上の「均等に分布」の画像を見ると200から255までの間にノイズが-均等に分布-していることがわかる。ということは255 から ( 255-「ノイズの量」 ) までのレベルにノイズが-均等に-分布していることがわかる。ただし、「ノイズの量」の最大値は999であるから、さらに、何らかの処理が加えられているのだろう。
同じように、「ガウス分布」の方もガウス分布の分散、中心値、ノイズ量を「ノイズの量」の数値に従い適当に導いているのだろう。大雑把にはわかった。
今回は濃度の分布に対する考察はここまでにしておく。次は位置分布である。今回のメインはこちらである。
まずは、下の図.3の拡大図を見て欲しい。
 |
そこで、Photoshopのノイズフィルタの位置分布に何らかの周期性があるのかどうかを調べてみたい。
そこで、それぞれのノイズ画像をフーリエ変換し周波数領域に変換する。
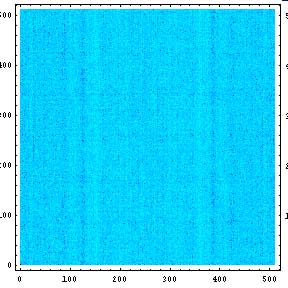 | 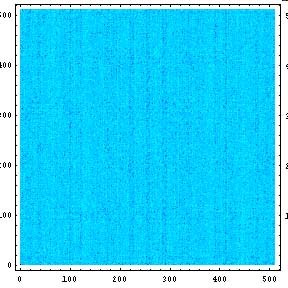 |
すると、縦線が見える。つまり、どちらも横方向に周期性があることがわかる。またそれよりレベルは小さいが縦方向にも周期性がある。それぞれの分布で周期性は異なっている。
横方向で一番レベルが大きいものは周期128ピクセルである。これはどちらの分布に関しても言えそうである。128とはいかにも納得できる数字である。
縦方向は85ピクセル位か?100位のもあるな? いずれ、より詳しい解析を行ってみたい。
さて、以前PhotoShopの乱数Pluginを作ろう。----FilterFactory編---(1999.01.08)で作成したプラグインはこんな周期性を持っていないことを保証しておく。以下がその証拠である。
 |  |
今回の結論:Photoshopのノイズフィルタには要注意である。
今回の教訓:何はともあれ疑ってかかれ。
1999-03-28[n年前へ]
■ハードディスクのエントロピーは増大するか?
デフラグと突然変異の共通点
fjでKByteの定義(よく言われる話だが)が話題になっていた。「なんで1024Byteが1KByteなんですか」というものである。そのスレッドの中で、
- 整数値だけでなく、分数値のbitもある
- 1bitのエントロピーも定義できるはずで、それならハードディスクは結構エントロピーを持つかも
初めに、「整数値だけでなく、分数値のbitもある」という方は簡単である。{0,1}どちらかであるような状態は1bitあれば表現できる。{0,1,2,3}の4通りある状態なら2bitあれば表現できる。{0,1,2,3,4,5,6,7}までなら3bitあればいい。それでは、サイコロのような状態が6通りあるものはどうだろうか? これまでの延長で行くならば、2bitと3bitの中間であることはわかる。2進数の仕組みなどを考えれば、答えをNbitとするならば、2^N=6であるから、log_2 ^6で2.58496bitとなる。2.58496bitあれば表現できるわけだ。
後の「1bitのエントロピーも定義できるはず」というのはちょっと違うような気もする。そもそもエントロピーの単位にもbitは使われるからだ。しかし、ハードディスクのエントロピーというのはとても面白い考えだと思う。
そこで、ハードディスクのエントロピーを調べてみたい。
次のような状態を考えていくことにする。
- きれいにハードディスクがフォーマットされている状態。
- ハードディスクの内容が画像、テキストファイル、圧縮ファイル、未使用部分に別れる。
- その上、フラグメントが生じる。
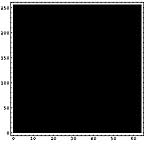
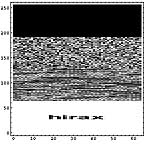
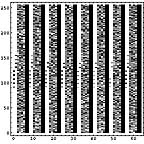
画像ファイル、テキストファイル、圧縮ファイル、未使用部分を1Byteグレイ画像データとして可視化してみる。
 |  |  |  |
ところで、このような可視化をすると、ファイルの種類による差がよくわかる。てんでばらばらに見えるものは冗長性が低いのである。逆に同じ色が続くようなものは冗長性が高い。こうしてみると、LZH圧縮ファイルの冗長性が極めて低いことがよくわかる。逆に日本語テキストデータは冗長性が高い。もちろん、単純な画像はそれ以上である。
それでは、これらのようなファイルがハードディスクに格納された状態を考える。
- きれいにハードディスクがフォーマットされている状態。
- ハードディスクの内容が画像、テキストファイル、圧縮ファイル、未使用部分に別れる。
- その上、フラグメントが生じる。
 |  |  |
横方向の1ライン分を一区画と考える。ハードディスクならセクタといったところか。その区画内でのヒストグラムを計算すると以下のようになる。この図では横方向が0から255までの存在量を示し、縦方向は区画を示している。
 | 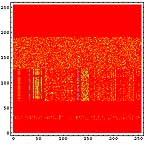 | 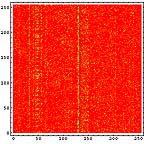 |
LZH圧縮ファイル部分では0から255までのデータがかなり均等に出現しているのがわかる。日本語テキストデータなどでは出現頻度の高いものが存在しているのがわかる。
それでは、無記憶情報源(Zero-memory Source)モデルに基づいて、各区画毎のエントロピーを計算してみる。
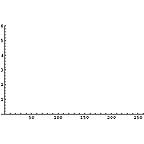 | 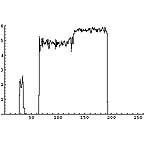 | 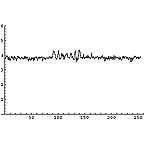 |
これを見ると次のようなことがわかる。
- 未使用ハードディスクは全区画にわたりエントロピーは0である
- 3種類のファイルが格納された状態では、それぞれエントロピーの状態が違う。
- 画像ファイルでは複雑な画像部分がエントロピーが高い
- 日本語テキストファイル部分は結構エントロピーが高い。
- LZH圧縮ファイル部分はエントロピーが高い。
- フラグメントが生じると、トータルではエントロピーが高くなる。
- しかし、平均的に先のLZH圧縮ファイル部分の状態よりは低い。
0 | 691.28 | 982.139 |
というわけで、今回の結論
「ハードディスクのエントロピーは増大する。」
が導き出される。もし、ハードディスクのデフラグメントを行えば、エントロピーは減少することになる。
こういった情報理論を作り上げた人と言えば、Shannonなのであろうが、Shannonの本が見つからなかったので、今回はWienerの"CYBERNETICS"を下に示す。もう40年位の昔の本ということになる。その流れを汲む「物理の散歩道」などもその時代の本だ。
 |
生物とエントロピーの関係に初めて言及したのはシュレディンガーだと言う。ハードディスクと同じく、企業や社会の中でもエントロピーは増大するしていくだろう。突然変異(あるいは、ハードディスクで言えばデフラグメント)のような現象が起きて、エントロピーが減少しない限り、熱的死(いや企業や会社であれば画一化、平凡化、そして、衰退だろうか)を迎えてしまうのだろう。
1999-04-26[n年前へ]
■WEBページは会社の顔色
WEBページのカラーを考える 2
前回は、WEBのレイアウトで企業についての考察を行った。今回はWEBページの色空間を考察してみたい。目的は、企業間あるいは、日本とアメリカ間で使用される色についてなにか差があるか、ということを調べることである。例えば、
- 日本では万年筆のインクには黒がほぼ使用されるが、アメリカなどでは青が使用されることも多い
- 日本で二色刷りでは黒と赤だが、アメリカでは黒と青である
まずは、ごく単純なCIE Lab色空間での考察を行いたい。CIE Lab色空間はCIE(Commission Internationale d'Eclairage= 国際照明委員会 )が1976年に推奨した、色空間であり、XYZ表色系を基礎とするものである。知覚的な色差を考えたいので均等色空間であるLab色空間を選んだ。
まずは、Lab色空間がどんなものかを以下に示す。これは、適当に書いてみたものなので、正確なものではない。もっとわかりやすいものが
http://www.sikiken.co.jp/col/lsab.htm
にある。
/ b*黄色 緑方向← 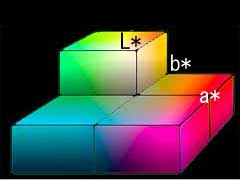 →a* 赤方向 →a* 赤方向青 / ↓暗い |
それでは、a*b*だけ表示してみる。以下がa*b*色平面である。これも大雑把なイメージ図である。
 →a* →a* |
参考までに、RGBからL*a*b*への変換式を挙げておく。
岡野氏のDigital AstronomyGallery ( http://www.asahi-net.or.jp/~RT6K-OKN/ )
から辿れる蒔田剛氏による第2回CCDカンファレンス「CANP'98」の「デジタル画像と色彩理論の基礎」によれば、
X= 0.412391R + 0.357584G + 0.180481B
Y= 0.212639R + 0.715169G + 0.072192B
Z= 0.019331R + 0.119195G + 0.950532B
ここで使用されているのRGB、およびその際の係数はハイビジョンテレビのRGB色空間だそうだ。
X0 = 0.95045 Y0 = 1.0 Z0 = 1.08892
とすれば、
L= 116(Y/Y0)^0.333 -16 ( Y/Y0 > 0.008856 )
a= 500[ (X/X0)^0.333 - (Y/Y0)^0.333 ]
b= 200[ (Y/Y0)^0.333 - (Z/Z0)^0.333 ]
とできるとある。もちろん、ここで使われる係数などは考えるデバイスにより異なるので、これは単なる一例である。
それでは、前回に使用した画像についてLab色空間でのヒストグラムを調べてみる。
| L*a*b*の平均値/標準偏差 | L*a*b*の平均値/標準偏差 | |||
| apple |  | L* 201/69.6 201/69.6a*  128/1.82 128/1.82b*  127/3.93 127/3.93 |  | L* 228/54.8 228/54.8a*  128/1.82 128/1.82b*  126/6.70 126/6.70 |
| sgi |  | L* 228/49.2 228/49.2a* 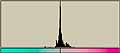 128/5.20 128/5.20b*  129/8.49 129/8.49 |  | L* 223/55.3 223/55.3a* 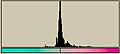 129/8.46 129/8.46b*  129.10.4 129.10.4 |
| Kodak |  | L*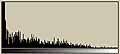 37.8/49.9 37.8/49.9a* 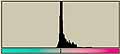 133/9.14 133/9.14b* 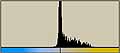 138/17.0 138/17.0 |  | L* 194/76.4 194/76.4a* 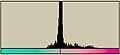 132/14.1 132/14.1b* 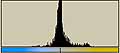 132/14.1 132/14.1 |
| Canon |  | L* 163/77.6 163/77.6a* 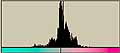 131/16.2 131/16.2b* 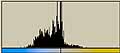 112/21.5 112/21.5 |  | L*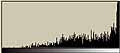 207.52.8 207.52.8a* 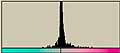 130/8.56 130/8.56b* 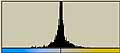 127/11.2 127/11.2 |
| FUJIFILM |  | L*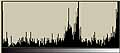 159/77.1 159/77.1a* 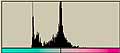 112/25.5 112/25.5b* 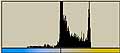 145/25.8 145/25.8 |  | L*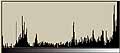 190/79.2 190/79.2a* 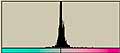 129/6.18 129/6.18b* 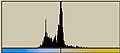 121/14.6 121/14.6 |
| Xerox |  | L* 191/80.1 191/80.1a* 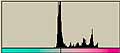 140/25.7 140/25.7b* 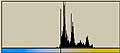 147/17.8 147/17.8 |  | L*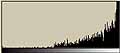 219/38.9 219/38.9a*  132/12.7 132/12.7b* 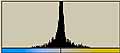 128/14.5 128/14.5 |
| RICOH |  | L*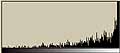 228/44.1 228/44.1a* 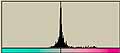 129/8.81 129/8.81b* 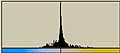 128/10.0 128/10.0 |  | L* 289/51.6 289/51.6a* 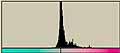 132/10.2 132/10.2b* 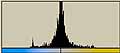 127/10.2 127/10.2 |
ここらへんまで、作業をしてくると、今回のやり方は失敗だったことがやっとわかる。WEBのトップページは企業のイメージカラーの影響が強すぎるし、こういった考察には数をかせぐ必要があるので、解析ロボットをつくって、ネットワーク上に放つ必要がある。手作業ではとてもじゃないがやってられない。
例えば、「WEBのトップページは企業のイメージカラーの影響が強すぎる」というのは
- Kodakアメリカの黄色
- FUJIFILMアメリカの緑
- Xeroxアメリカの赤
- Canonアメリカの青
ところで、Canonに関しては日本版を見るにイメージカラーは赤のような気がするが、アメリカ版では明らかに青をイメージカラーとしている。これは、Xeroxとの兼ね合いだろうか?
さて、今回の考察はやり方を間違えたので話が発散してしまった。要反省だ。
1999-09-08[n年前へ]
■続ACIIアートの秘密
階調変換 その1
さて、今回は
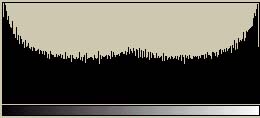
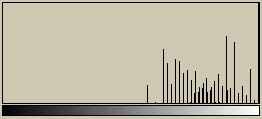
の続きである。今回はASCIIアートの階調変換に関する話である。原画像からASCII文字画像に変換するときにどう変換するか、という話の第一話である。 まずは、白から黒までの256階調の基準チャートとASCII文字によるチャートを示してみよう。
両者ともかなり縮小表示している。従って、ASCII文字チャートの方は文字がつぶれて滑らかに見えている。一見すると、ASCII文字チャートの方は白地に黒い文字を印字しているため、完全に黒いようなものは出力できない。そのため、全体的に白く見える。
これらの2つの画像のヒストグラムを示してみよう。ばらつきが多少あるが、256階調の基準チャート(上)では256階調にわたって存在している。しかし、ASCII文字チャート(下)では(ざっと見た限りでは)35階調程度しか存在していない(これは使用するフォントによって異なる)。もともと、ASCII文字は数多くあるわけではないし、平均濃度が等しい文字も存在するので、この程度になってしまうのはしょうがない。また、最も黒い領域でも、256階調の基準チャート(上)の半分程度の濃度しかない(これも使用するフォントによって異なる)。
ところどころに「使用するフォントによって異なる」という注釈を入れいるがこれが前回作成したimage2asciiの特徴である。指定のフォントを用いて画像出力を行った結果を用いてガンマテーブルを再構成するのである。逆にいえば、その指定のフォントを用いない場合には意図した画像は得られないわけである。「DeviceDepend」な技術というわけである。
 |
 |
そもそも、オリジナルの画像から、この程度の階調しかないASCII文字画像へどのように変換したら良いだろうか? 先に基準チャート(上)とASCII文字チャートの例を示したが、そもそもそのASCII文字チャートはどのようにして変換するのだろうか?
まず思いつくのはオリジナル画像の濃度に一番近い濃度の出力を行う方法である。それを濃度精度重視の変換と呼ぼう。そして、もうひとつは、オリジナル画像の中での相対濃度を基準とする変換である。すなわち、オリジナルの最大濃度をASCII文字出力による最大画像に合わせ、オリジナルの最小濃度をASCII文字出力による最小画像に合わせ、あとは単に線形に変換する方法である。こちらを(まずは単純な)階調性重視の変換と呼ぼう。その変換の構造を以下に示してみる。
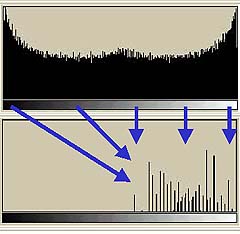 | 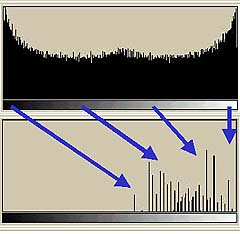 |
濃度精度重視の変換(左)では、ある濃度以上になると全て同じ濃度で示されてしまう。階調性重視の変換(右)ではそんなことは生じない。しかし、オリジナルの画像と変換後の画像の濃度はかなり異なってしまう。これら2つのやり方によるASCII文字チャートをそれぞれ示してみる。
濃度精度重視によるASCII文字チャートと階調性重視によるASCII文字チャート(下)のどちらが自然だろうか?濃度精度重視によるASCII文字チャートは階調の中程までは基準チャート(上)と非常に近い濃度を保っている。そのかわり、それ以降の濃度が高い部分はまったく階調性を失っている。少なくともこの基準チャート(上)のように256階調にわたり均等に濃度が存在するような画像を扱うのであれば、階調性重視によるASCII文字チャート(下)の方が自然だろう。というわけで、前回作成したimage2asciiは階調性重視による変換を用いている。
さて、今回は256階調全てにわたって滑らかな基準チャートを用いて考えてみた。しかし、実際の写真はそんなものではない。色々な濃度が均等に現れるわけではないし、そもそも狭い濃度領域しかない画像の場合もあるそういった場合には、数多くの問題が生じる。また、単に(単純な)階調性重視によるASCII文字チャート(下)が優れているわけでもなくなる。場合によって何が優れているかは異なるのだ。一般的な画像において、一体どんな問題が生じるのか、ということを次回に考えてみることにする。そして、新たに2種類の変換方法を加えてバージョンアップしたimage2asciiの登場するわけである。
今回は、その3つの変換方法の違いにより出力画像にどのような違いが生じるかを示すだけにしておく。先入観が無い状態で、優劣を判断してみると良いと思う。次の例は人物写真である。まずは、オリジナルの写真である。
 |
以下にimage2asciiを用いて変換したものを示す。
 |  |  |
これらの違いがどのようなものであるかを次回に考える。